Ho scoperto di recente LMSYS Chatbot Arena, che in particolare offre due servizi interessanti:
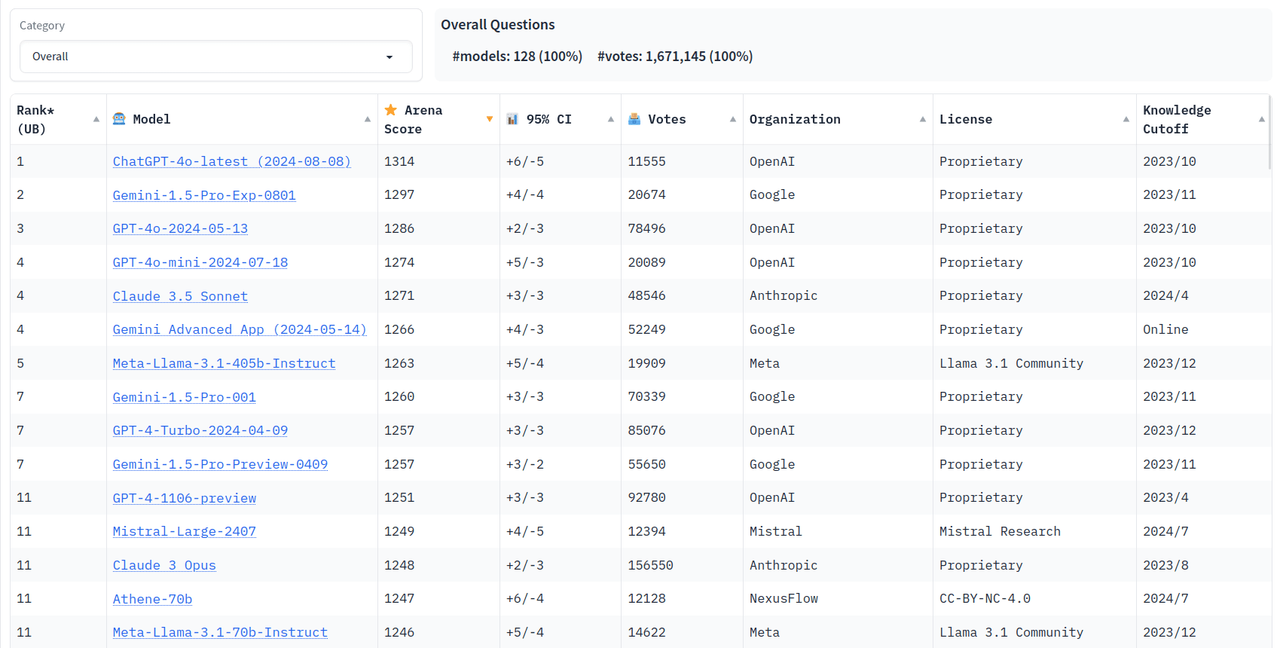
- LMSYS Chatbot Arena Leaderboard: ranking per uso generale ("overall"), che vede ad esempio ChatGPT-4o-latest (2024-08-08) in prima posizione, seguito da Gemini-1.5-Pro-Exp-0801, ecc; è possibile selezionare poi varie categorie e quindi mostra una classifica per quella specifica categoria, ad esempio "Math" ha in prima posizione Claude 3.5 Sonnet mentre ChatGPT-4o-latest (2024-08-08) in seconda; "Coding" ha sempre in prima posizione ChatGPT-4o-latest (2024-08-08), "French" _ ha in prima posizione Gemini App (2024-01-24); quindi è molto importante riconoscere che per un compito specifico un LLM (Large Language Model ovvero ciò che sta alla base di un software tipo chatbot) può essere più abile un determinato modello, rispetto ad un uso generale in cui ad oggi ChatGPT-4o-latest (2024-08-08) ha la meglio
- LMSYS Chatbot Arena (Multimodal): Benchmarking LLMs and VLMs in the Wild: qui possiamo fornire in input un testo e vengono proposte due risposte, "Model A" e "Model B" (che vengono scelti dal sistema in modo random); poi ci viene chiesto quale delle due ci sembra essere la migliore, o pareggio; per non influenzare il voto, solo dopo aver votato vediamo quali erano i due modelli; quindi la nostra eventuale valutazione può aiutare a definire meglio il benchmark complessivo
È interessante per due ragioni, sia per farsi un'idea generale, sia anche per testare contemporaneamente due modelli, quindi se non abbiamo esigenza di un chatbot specifico magari continuando su un'unica conversazione, in questo modo possiamo confrontare in modo immediato due risposte di due modelli differenti e la cosa può essere molto utile sia per completezza generale, sia affidabilità nella risposta (controllo incrociato, se entrambe le risposte sono analoghe, è più probabile che sia corretto).
Cosa ne pensate? Ne eravate a conoscenza? Vi piace? 🙂