Ho pensato di implementare un algoritmo che mi incuriosiva da tempo (realizzarlo però non era semplice), ovvero un'applicazione del calcolo distribuito! Dalla definizione di calcolo distribuito:
computer autonomi che interagiscono/comunicano tra loro attraverso una rete al fine di raggiungere un obiettivo comune
Nella pratica l'idea è affascinante, specie nella programmazione, se ho due o più PC possiamo pensare quindi di poter unire le rispettive potenze di calcolo!
Calcolo distribuito: come applicarlo in pratica, unire la potenza di calcolo di due (o più) computer
Nella pratica, possiamo fare questo:
- lavorare a livello di rete locale, rete LAN
- lavorare a livello di rete globale (ad esempio tramite un software come Dropbox)
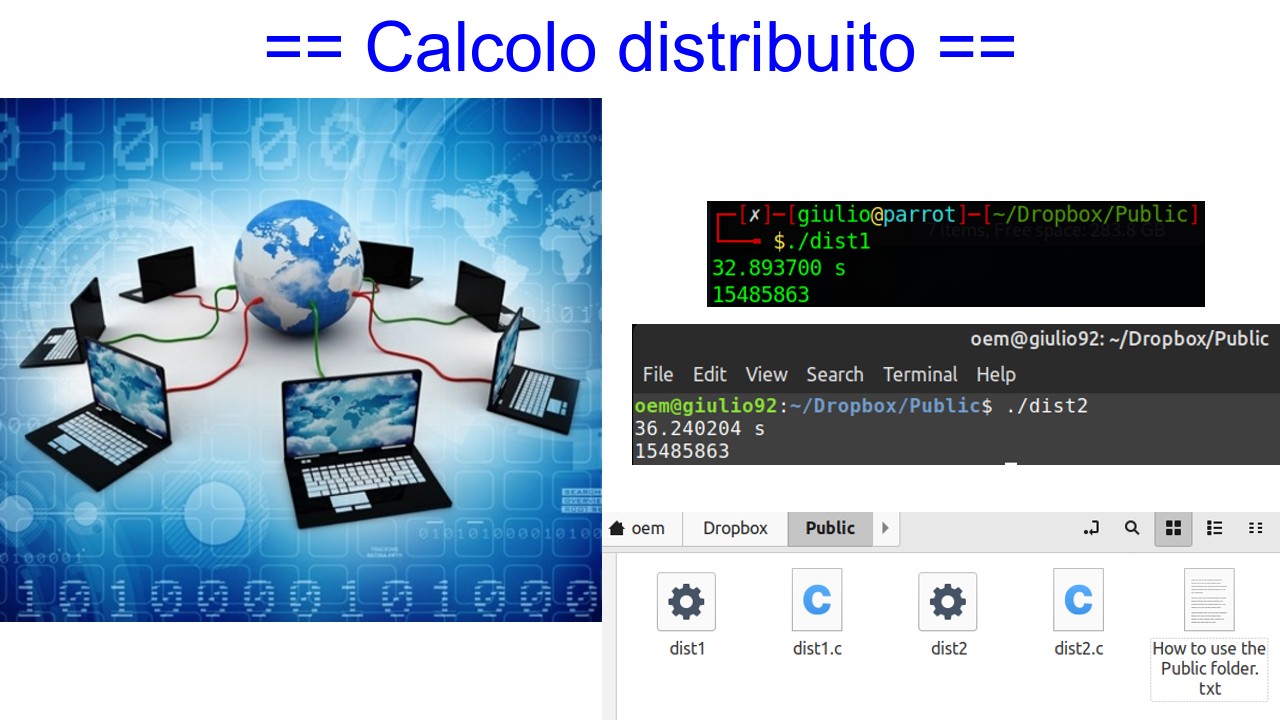
Ho scelto il secondo esempio, anche se meno efficiente (una rete locale avrebbe ovviamente velocità superiore), poiché risulta comunque più versatile, teoricamente dall'accesso di una cartella condivisa online, qualsiasi computer connesso a internet potrebbe partecipare allo scopo. Nello specifico ho installato Dropbox su due computer (due distribuzioni Linux diverse), già l'installazione di Dropbox su Linux può essere un'impresa 😅
Come algoritmo, si potrebbe implementare di tutto, a seconda delle esigenze. Nel mio caso ho semplicemente fatto questo: un programma per il calcolo del primo milione di numeri primi (spoiler: il milionesimo numero primo, se vi interessa saperlo, è 15485863), tratto dall'ispirazione di una mia vecchia discussione, Algoritmi per numeri primi: risultati, benchmark; algoritmo così suddiviso:
- dist1.c: programma numero 1, che fa uso di un algoritmo
- dist2.c: programma numero 2, che fa uso di un altro algoritmo
- al termine di uno dei due, viene creato un file (dist1.txt o dist2.txt a seconda di chi dei due finisce prima), l'altro programma in esecuzione controlla periodicamente la presenza di tale file e nel caso ci sia, termina poiché non ha più senso continuare l'esecuzione
In questo caso, sappiamo che dist1 è l'algoritmo che vince (da come è scritto, era cosa nota), poi nella pratica con Dropbox (rete globale, non locale) c'è un po' di delay e infatti dist2 termina dopo circa tre secondi (un po' è dovuto al delay della rete, un po' anche al fatto che il controllo della presenza del file non è istataneo altrimenti risulterebbe inefficiente per questa ragione, dover controllare milioni di volte se è presente il file in modo da terminare prima... Non avrebbe senso).
Nella pratica, questo algoritmo che ho scritto è da intendersi come esempio delle potenzialità del calcolo distribuito, qualcosa che di fatto FUNZIONA! Ho unito due computer, in questo caso per valutare contemporaneamente quale dei due algoritmo fosse più efficiente (con un unico computer, a parità di condizioni avrei avuto tempo doppio... Anche ben di più in realtà dato che l'algoritmo meno efficiente non avrebbe avuto un segnale di termine). Volendo, questo codice poteva essere reso ancora più efficiente ma come detto, ciò che conta era mostrare la possibilità di far funzionare un sistema di questo tipo.
Calcolo distribuito: pregi e difetti, difficoltà tecniche
- unire la potenza di calcolo di due o più computer: tanta roba!!
- dover scrivere un algoritmo specifico per ogni computer e gestire le interazioni (eh unire la potenza di calcolo non è come unire la memoria di massa ovvero collegamento tramite USB o simile 😁 )
Nel mio esempio quindi, si trattava di avviare due programmi in parallelo "senza perdere tempo": diverso comunque rispetto a non avere il calcolo distribuito ovvero semplicemente un programma per macchina senza interazione (connessione alla rete, verifica dello stato di esecuzione dell'altra macchina), poiché in quel caso avremmo continuazione dell'esecuzione del programma meno efficiente (che non può sapere che l'altro ha già finito!).
Altri esempi interessanti e complessi possono essere ad esempio una serie di operazioni matematiche svolte da un PC, che al termine salva un file con i risultati, poi va avanti con altre operazioni; l'altro PC prima eseguiva operazioni diverse e poi legge il file generato e in base a quello calcola altre operazioni, e così via.
Le potenzialità sono infinite, la cosa difficile ovviamente è creare un algoritmo in grado di gestire tutto ciò! 🙂
Riporto qui i due codici, prima dist1.c e poi dist2.c.
#include <stdio.h>
#include <stdbool.h>
#include <math.h>
#include <time.h>
bool is_prime(unsigned int numero) {
double radice = sqrt(numero);
if(numero%2==0){return false;}
for (register int i = 3; i <=radice; i+=2) {
if (numero % i == 0) {
return false;
}
}
return true;
}
int main() {
register unsigned int numero = 2;
register unsigned int contatore = 0;
register unsigned int N=1000000;
register unsigned short finished=0;
FILE *f2;
clock_t start = clock();
while (contatore < N-1) {
f2=fopen("dist2.txt","r");
if(f2!=NULL){finished=1;break;}
if (is_prime(numero)) {
contatore++;
}
numero++;
}
clock_t end = clock();
printf("%f s\n", (float)(end - start) / CLOCKS_PER_SEC);
if(finished==0){
FILE *f1=fopen("dist1.txt","w");
fprintf(f1," ");
fclose(f1);
}else{fclose(f2);}
printf("%d\n", numero - 1);
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <math.h>
#include <time.h>
bool is_prime(unsigned int numero) {
double radice = sqrt(numero);
for (int i = 2; i <= radice; i++) {
if (numero % i == 0) {
return false;
}
}
return true;
}
int main() {
register unsigned int numero = 2;
register unsigned int contatore = 0;
register unsigned int N=1000000;
register unsigned short finished=0;
FILE *f1;
clock_t start = clock();
while (contatore < N) {
f1=fopen("dist1.txt","r");
if(f1!=NULL){finished=1;break;}
if (is_prime(numero)) {
contatore++;
}
numero++;
}
clock_t end = clock();
printf("%f s\n", (float)(end - start) / CLOCKS_PER_SEC);
if(finished==0){
FILE *f2=fopen("dist2.txt","w");
fprintf(f2," ");
fclose(f2);
}else{fclose(f1);}
printf("%d\n", numero - 1);
return 0;
}
Infine un'immagine. Conoscevate il concetto di calcolo distribuito? Vi piace l'idea? 🙂